This Riddler puzzle is about repeatedly flipping coins!
On the table in front of you are two coins. They look and feel identical, but you know one of them has been doctored. The fair coin comes up heads half the time while the doctored coin comes up heads 60 percent of the time. How many flips — you must flip both coins at once, one with each hand — would you need to give yourself a 95 percent chance of correctly identifying the doctored coin?
Extra credit: What if, instead of 60 percent, the doctored coin came up heads some P percent of the time? How does that affect the speed with which you can correctly detect it?
Here is my solution.
[Show Solution]
The first thing to realize about this problem is that the answer depends on how the coin flips turn out. For example, suppose that after $n$ flips, both coins came up heads an equal number of times. This is unlikely, but nonetheless it’s possible. We obviously can’t conclude anything about the coins in such a case. So the answer can’t depend only on $n$.
The coin flips are independent. So if a coin comes up heads with probability $p$ and we flip it $n$ times, the probability that it comes up heads exactly $k$ times is given by a Binomial distribution:
\[
B(n,p,k) = {n \choose k} p^k (1-p)^{n-k}
\]Let’s say the coins are numbered 1 and 2 and their probabilities of coming up heads are $p_1$ and $p_2$ respectively.
Now for the experiment: we flip each coin $n$ times and record how many times they come up heads (but we don’t know which coin is which). Let’s say they come up heads $k_1$ and $k_2$ times for the left and right coin respectively. Let’s call the data we observed $k$. There are two possible scenarios:
- Coin 1 was in the left hand (and Coin 2 was in the right hand). We’ll call this scenario $\theta_1$. The likelihood of this scenario occurring is:
\[
\mathbb{P}(k\mid \theta_1) = B(n,p_1,k_1) B(n,p_2,k_2)
\] - Coin 1 was in the right hand (and Coin 2 was in the left hand). We’ll call this scenario $\theta_2$. The likelihood of this scenario occurring is:
\[
\mathbb{P}(k\mid \theta_2) = B(n,p_1,k_2) B(n,p_2,k_1)
\]
These are the only possible scenarios. If we want to be confident with level $\alpha$ about one of the scenarios then the posterior probability must be greater than $1-\alpha$. In other words:
- If $\mathbb{P}(\theta_1\mid k) > 1-\alpha$, then we are confident in Scenario 1.
- If $\mathbb{P}(\theta_2\mid k) > 1-\alpha$, then we are confident in Scenario 2.
Note that by definition, $\mathbb{P}(\theta_1\mid k)+\mathbb{P}(\theta_2\mid k) = 1$ for all $k$. So the two cases above can’t simultaneously be true when $\alpha\lt\tfrac{1}{2}$. We can compute posterior probability by using Bayes’ rule:
\[
\mathbb{P}(\theta_1\mid k) = \frac{\mathbb{P}(k\mid \theta_1)\mathbb{P}(\theta_1)}{\mathbb{P}(k\mid \theta_1)\mathbb{P}(\theta_1)+\mathbb{P}(k\mid \theta_2)\mathbb{P}(\theta_2)}
\]It is reasonable to assume that scenarios $\theta_1$ and $\theta_2$ have the same prior probability. So $\mathbb{P}(\theta_1)=\mathbb{P}(\theta_2)=\tfrac{1}{2}$. Therefore, our condition for confidence simplifies to:
\[
\frac{\mathbb{P}(k\mid \theta_1)}{\mathbb{P}(k\mid \theta_1)+\mathbb{P}(k\mid \theta_2)} > 1-\alpha
\quad\text{or}\quad
\frac{\mathbb{P}(k\mid \theta_2)}{\mathbb{P}(k\mid \theta_1)+\mathbb{P}(k\mid \theta_2)} > 1-\alpha
\]Rearranging these inequalities, we have:
\[
\frac{\mathbb{P}(k\mid \theta_1)}{\mathbb{P}(k\mid \theta_2)} > \frac{1-\alpha}{\alpha}
\quad\text{or}\quad
\frac{\mathbb{P}(k\mid \theta_2)}{\mathbb{P}(k\mid \theta_1)} > \frac{1-\alpha}{\alpha}
\]If we take logs of both sides, we can combine the expressions into a single inequality involving the difference of log-likelihoods, namely:
\[
\bigl|\, \log \mathbb{P}(k\mid \theta_1)-\log \mathbb{P}(k\mid \theta_2)\, \bigr| > \log\left(\tfrac{1}{\alpha}-1\right)
\]This has a nice interpretation: we can stop flipping coins once the difference between log-likelihoods grows sufficiently large. The smaller we make $\alpha$, the larger the difference in log-likelihoods must be before we can declare that we are confident.
We can simplify the expression considerably by substituting the definitions for the likelihoods $\mathbb{P}(k\mid \theta_1)$ and $\mathbb{P}(k\mid \theta_2)$ in terms of the $B(\cdot)$ functions, and substituting the binomial probability mass functions. Doing this, we obtain the simpler expression:
\[
|k_1-k_2| \left|\, \log \left( \tfrac{1}{p_1}-1 \right)-\log\left(\tfrac{1}{p_2}-1\right) \,\right| > \log\left(\tfrac{1}{\alpha}-1\right)
\]Note that $p_1$, $p_2$, $\alpha$ are parameters of the problem. The only part that change from case to case is $k_1$ and $k_2$. While it is customary to use a normal approximation when dealing with binomial distributions, doing so actually produces a more complicated formula, so we stick with binomials. The dependence on $n$ becomes evident if we express this formula in terms of the empirical probabilities $\hat p_1 := k_1/n$ and $\hat p_2 := k_2/n$. We obtain:
$\displaystyle
n \,>\, \frac{1}{|\hat p_1-\hat p_2|} \frac{\log\left(\frac{1}{\alpha}-1\right)}{\left|\, \log(\tfrac{1}{p_1}-1)-\log(\tfrac{1}{p_2}-1) \,\right|}
$
This is exactly the sort of expression we’re after — a lower bound on the number of samples required. This result agrees with our initial intuition: if $\hat p_1-\hat p_2 \to 0$, then $n\to \infty$. If the proportion of heads for both coins is the same, then we can’t possibly infer anything!
Expected solution. The number of flips required will be different depending on how the flips turn out. One way to get a numerical solution is to assume that the empirical probabilities match the true probabilities. In this case, we can substitute the values $\hat p_1 = p_1=0.5$, $\hat p_2 = p_2=0.6$, and $\alpha=0.05$ into the formula above, and we obtain $n \approx 73$.
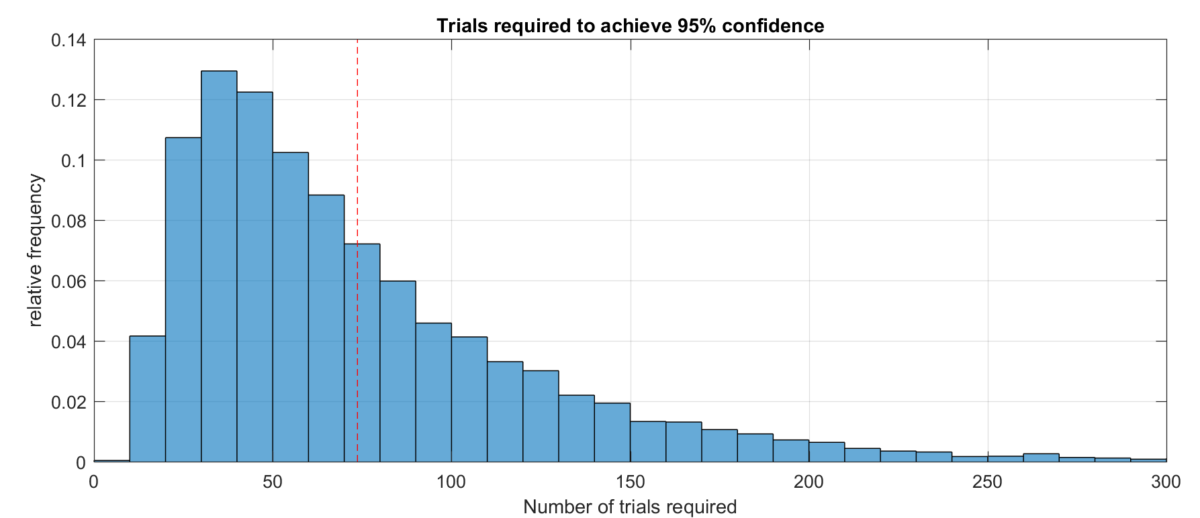
We can also simulate: generate random coin flips, compute empirical probabilities, and record how many flips were required to satisfy the 95% criterion. Then repeat many times and plot the distribution of stopping times. Here is what you get when you do this with 10,000 trials.

This distribution is very broad; sometimes only a dozen flips are required, other times over 300 flips are required. But the mean of the distribution (indicated in red) is close to our approximation of 73.
Varying the probability. We can also see what happens to the mean stopping time as we change the probability. Here, I assumed that $\hat p_1 = p_1 = 0.5$ and I plotted the average number of flips required to achieve 95% confidence as a function of $p_2$. Here is what I got:

As $p_2$ gets closer to $0.5$ (which is the value of $p_1$), it takes more and more flips to be able to tell the coins apart.