It was an honor and a privilege to be one of eight invited speakers at the bi-annual NCCR Automation Symposium. The symposium was hosted in-person at ETH Zürich in May 2022.
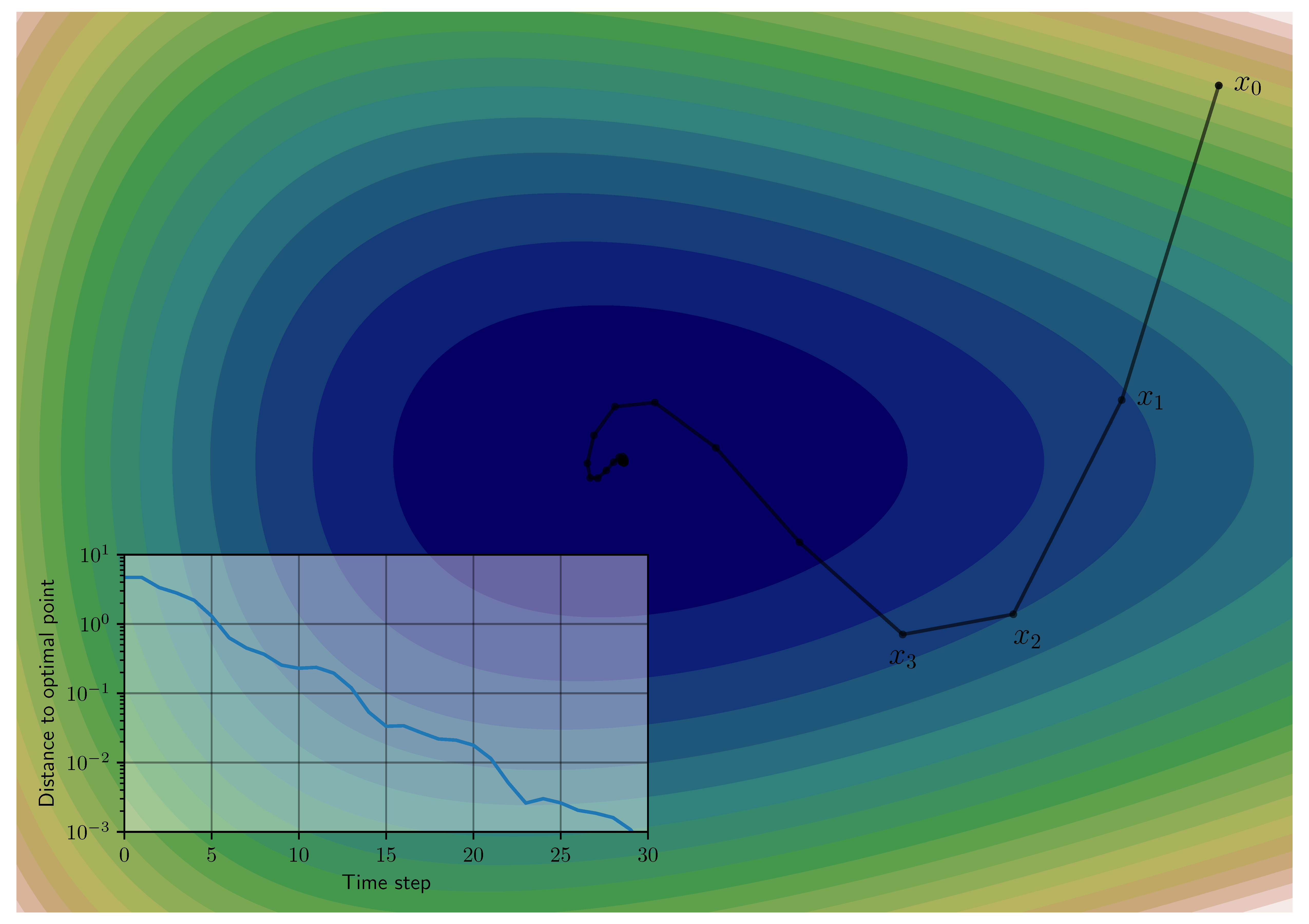
The theme of this symposium was “Systems Theory of Algorithms”. As explained on the symposium website, many iterative algorithms in optimization, games, and learning can be viewed as dynamical systems evolving over time with inputs (real-time signals, historic data samples, or random seeds), outputs (decision variables or algorithm iterates), and uncertainties (noise or unknown problem parameters). The dynamical systems perspective on such algorithms is key in future automation, AI, and socio-technical systems, where challenges arise from the analysis and design of algorithms
Continue reading →